Partition plays a core role in Kafka, it affects Kafka’s storage structure and the way Kafka produce and consume messages. It’s very important for us to fully understand the partition before we do a deep dive into the Kafka. In this article, I will show the concept, structure and the role it plays in Kafka.
Essential of Kafka Workflow
To start with, we will need to have some basic understanding over some other concepts in Kafka like Event, Stream and Topic before we go to the partition. First, let’s get the definition of those terms:
- Event -> It represents something happened in the past, usually stands for a message or a record.
- Event is immutable, once the a event occurs, it cannot be changed.
- Stream -> It represents all related events during a particular event movement flow.
- Topic -> It represents the details of a stream, just like a static stream. The topic organizes all relative events and storage them just like a table in a database.
The image below shows the concepts I mentioned above.

Now, Partition
In the above session, we get to know what a topic stands for in Kafka, and how it looks(Just like a table in a database). This is important, because partition is a part of a topic. Think about the binary log of a MySQL database. Every change in a mysql table(insert, update…) will be recorded to the binary log. The same thing happens on topic, a partition records every message under a topic. In Kafka, partition is the smallest storage unit.
See the below diagram:
Offsets of Partition
When we are first getting to use Kafka, we will often see the offsets alongside with partition when we set up our consumers. Inside a partition, messages are stored in a timely order, each message will come with a unique code called offset. Just like a primary key in a relational database with auto increment, offset is an auto increment, unchangeable number auto assigned by Kafka. When a message was written into a partition, it will be added to the end of the partition and get a number assigned as offset.
With offset implemented as the indicator of message order, many people will think messages inside a topic is ordered and they can track the message with an offset. This is not 100% true, indeed, with offset, we can track a message inside a partition, but remember, a topic is usually made up of multi partitions. Thus, even if the messages inside a partition are ordered, the messages across different partitions will remain unordered. The below diagram shows how messages are ordered inside a single partition and across the whole topic.
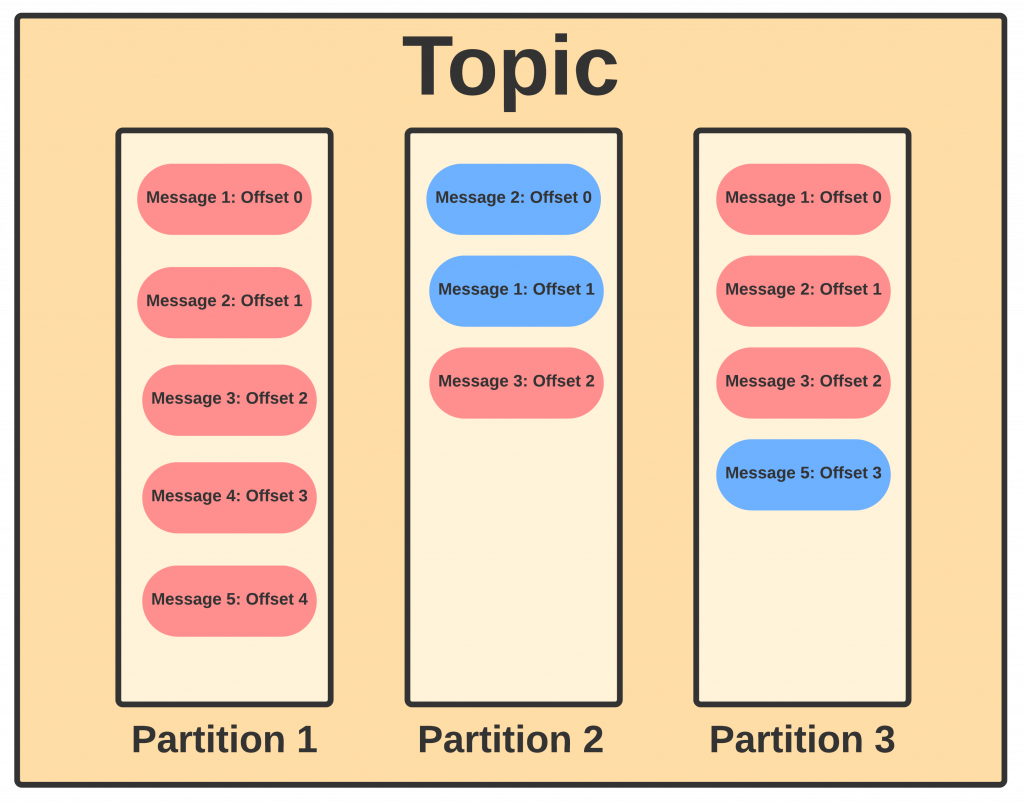
In the above diagram, we assume that in partition 1, message 1 to 5 is sent by producer in order, and partition 1 received them in order. Thus, in partition 1, offset is the same order as the order the producer sent. But for partition 2, for some reason, it might receive the message 1 and message 2 in reverse order, in this way, we can easily see the offset 1 in partition 1 is not the same as the offset in partition 2. But this is a rare case, the more common cases we will meet is the one in partition 3 where a message is missing in between the transition of messages, in this way our offset 3 is not pointing into message 4, instead, it points to the latest message which is message 5.
The benefits of using partition.
There are many benefits of using partitions. The first one is it extend availability of Kafka. Usually, a Kafka cluster will have multi brokers(server). And each broker will have part of the cluster data by using partitions. Kafka will distribute multi partitions over multi brokers, and the benefits of doing this are:
- If all partitions are on a single broker. Due to the limitation of single server IO. It will be hard to extend the system load horizontally.
- A Kafka topic usually is consumed by multi consumers, there is a limitation of number of consumer that a single broker can hold. When setting up multi partitions over multi brokers, it can hold more consumers and we can extend its capacity by adding more brokers.
- Inside a consumer, it can have multi instance, we can let each instance connect to a partition, in this way. A consumer can getting data from multi brokers to speed up the process.
- Partitions can be used as a back up. If one partition fail, we can easily get the same data(maybe different order) from other partitions.
Write Into Partition
Since a topic will have multi partition, when we producer messages to a topic, there are several methods to indicate Kafka about which partition we will be writing into:
- Partition Key: When the producer is sending a message, we can set up a key(partition key), it can be any data that is related to the message you sent(id, name). With the key, Kafka will run a hash function over the partition key and decide which partition it will go to.
- Send Without Key: If a message is sent without any key, Kafka will insert this message into partitions based on load-balance. In this case, messages will be unordered.
- Customized Rules: You can set up and apply your own rule to tell Kafka how to write messages into partitions.
Read From Partition
Unlike other MQ, Kafka is not going to push the messages to the consumer, instead, the consumers will need to pull messages from partitions. A customer will try to connect to partitions of a broker and read messages from it in order. And offset here acts as an indicator to tell the consumer about the last message it pulled before.
Besides from that, some times, we can group consumers into a consumer group which has a group id to make sure a message is only to be read by consumers inside this consumer group once. For example, if we have an backend application that have 10 replicas, we can set them to be the same group id. So they will not read the same data and record into their own databases 10 times. And it’s also a good way to prevent that service from down. If one of the ten application failed, another consumer in the remaining 9 applications will take up the old consumer and keep the data flow going without any downtime.